One-sided vs. two-sided tests, and data snooping
Last updated on 2024-03-12 | Edit this page
Estimated time: 10 minutes
Overview
Questions
- Why is it important to define the hypothesis before running the test?
- What is the difference between one-sided and two-sided tests?
Objectives
- Explain the difference between one-sided and two-sided tests
- Raise awareness of data snooping / HARKing
- Introduce further arguments in the
binom.testfunction
A one-sided test
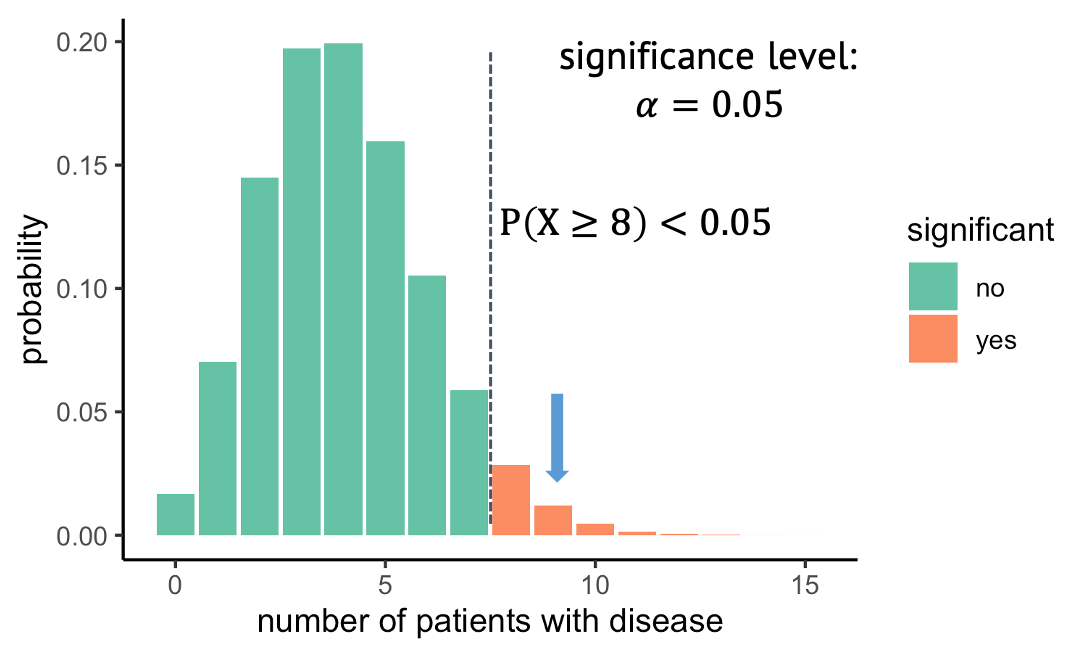
What you’ve seen in the last episode was a one-sided test, which means we looked at only at one side of the distribution. In this example, we observed 9 out of 100 persons with disease, then we asked: What is the probability under the null, to observe at least 9 persons with that disease. And we rejected all the outcomes where this probability was lower than 5%. The alternative hypothesis that we then take on is that the prevalence is larger than 4%. But we could just as well have looked in the other direction and have asked: What is the probability of seeing at most the observed number of diseased under the null, and then in case of rejecting the null, we’d have accept the alternative hypothesis that the prevalence is below 4%.
Let me remind you how we initially phrased the research question and the alternative hypothesis: We wanted to test whether the prevalence is different from 4%. Well, different can be smaller or larger. So, to be fair, this is what we should actually do:
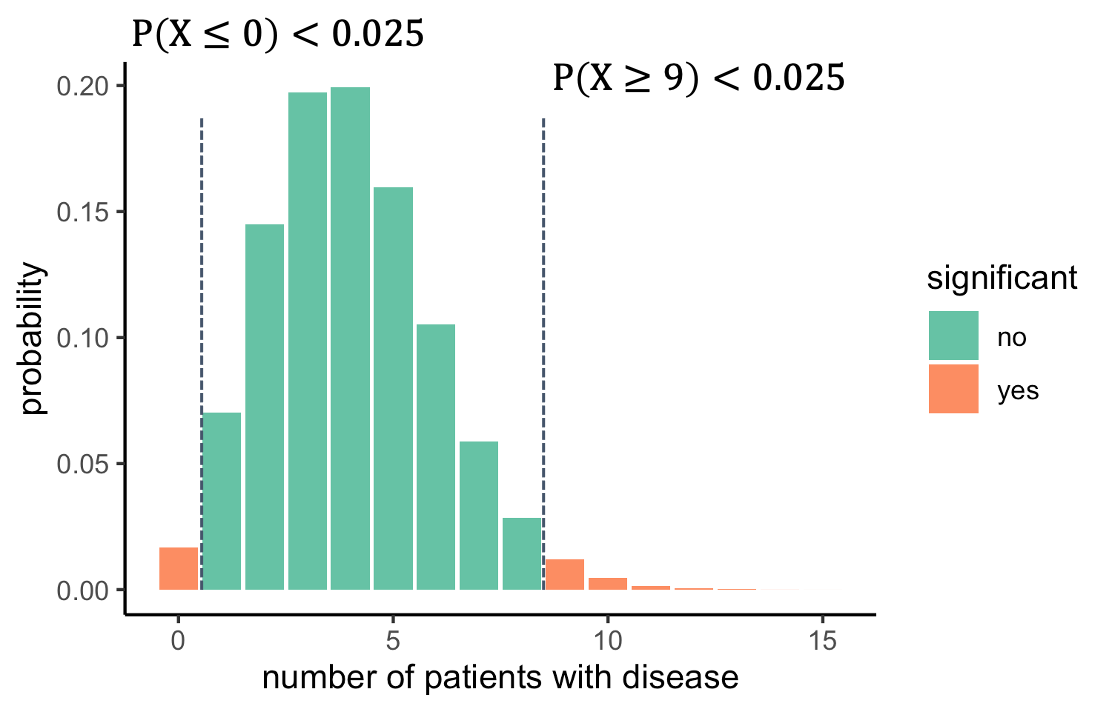 We should look on both sides of the distribution and ask
what outcomes are unlikely. For this, we split the 5% significance to
2.5% on each side. That way, we will reject everything below 1, or above
8. The alternative hypothesis is now that the prevalence is different
from 4%.
We should look on both sides of the distribution and ask
what outcomes are unlikely. For this, we split the 5% significance to
2.5% on each side. That way, we will reject everything below 1, or above
8. The alternative hypothesis is now that the prevalence is different
from 4%.
But what exactly was wrong with a one-sided test? An observation of 9 is clearly higher than the expected 4, so no need to test on the other side, right? Unfortunately: no.
Excursion: Data snooping / HARKing
What we did is called HARKing, which stands for
“hypothesis after results known”, or, also data snooping.
The problem is, we decided on the direction to look at after having seen
at the data, and this messes with the significance level \(\alpha\). The 5% is just not true
anymore, because we spent all the 5% on one side, and we cheated by
looking into the data to decide which side we want to look at. But if
the null were true, then there would be a (roughly) 50:50 chance that
the test group gives you an outcome that is higher or lower than the
expected value. So we’d have to double the alpha, and in reality it
would be around 10%. This means, assuming the null was true, we actually
had an about 10% chance of falsely rejecting it.
Side note
Above it says that there is a ~50% chance of the observation being below 4, and that a one-sided test after looking into the data had a significance level of ~0.1. The numbers are approximate, because a binomial distribution has discrete numbers. This means that
- there’s not actually an outcome where the probability of seeing an
outcome as high as this or higher is exactly 5%.
- it’s actually more likely to see an outcome below 4 (\(p=0.43\)), than seeing an outcome above (\(p=0.37\)). The numbers don’t add up to 1, because there is also the option of observing exactly 4 (\(p=0.2\)).
One-sided and two-sided tests in R
Many tests in R have the argument alternative, which
allows you to choose the alternative hypothesis to be
two.sided, greater, or less. If
you don’t specify this argument, it defaults to two.sided.
So it turns out, in the exercise above, you did the right thing
with:
R
binom.test(9,100,p=0.04)
OUTPUT
Exact binomial test
data: 9 and 100
number of successes = 9, number of trials = 100, p-value = 0.01899
alternative hypothesis: true probability of success is not equal to 0.04
95 percent confidence interval:
0.0419836 0.1639823
sample estimates:
probability of success
0.09 A one-sided test would be:
R
binom.test(9,100, p=0.04, alternative="greater")
OUTPUT
Exact binomial test
data: 9 and 100
number of successes = 9, number of trials = 100, p-value = 0.01899
alternative hypothesis: true probability of success is greater than 0.04
95 percent confidence interval:
0.04775664 1.00000000
sample estimates:
probability of success
0.09 It’s a little bit confusing that both tests give a similar p-value here, which is again due to the distribution’s discreteness. Using different numbers will show how the p-value for the same observation is lower if you choose a one-sided test:
R
binom.test(27, 100, p=0.2)$p.value
OUTPUT
[1] 0.102745R
binom.test(27, 100, p=0.2, alternative="greater")$p.value
OUTPUT
[1] 0.05583272Challenge: one-sided test
In which of these cases would a one-sided test be OK?
- The trial was conducted to find out whether the disease prevalence
is increased due to the precondition. In case of a significant outcome,
persons with the preconditions would be monitored more carefully by
their doctors.
- You want to find out whether new-born children already resemble their father. Study participants look at a photo of a baby, and two photos of adult men, one of which is the father. They have to guess which of them. The hypothesis is that new-borns resemble their fathers and the father is thus guessed >50% of the cases. There is no reason to believe that children resemble their fathers less than they resemble randomly chosen men.
- When looking at the data (only 1 out of 100), it becomes clear that the prevalence is certainly not increased by the precondition. It might even decrease the risk. We thus test for that.
In the first and second scenario, one-sided tests could be used. There are different opinions to how sparsely they should be used. For example, Whitlock and Schluter gave the second scenario as a potential use-case. They believe that a one-sided test should only be used if “the null hypothesis are inconceivable for any reason other than chance”. They would likely argue against using a one-sided test in the first scenario, because what if the disease prevalence is decreased due to the precondition? Wouldn’t we find this interesting as well?